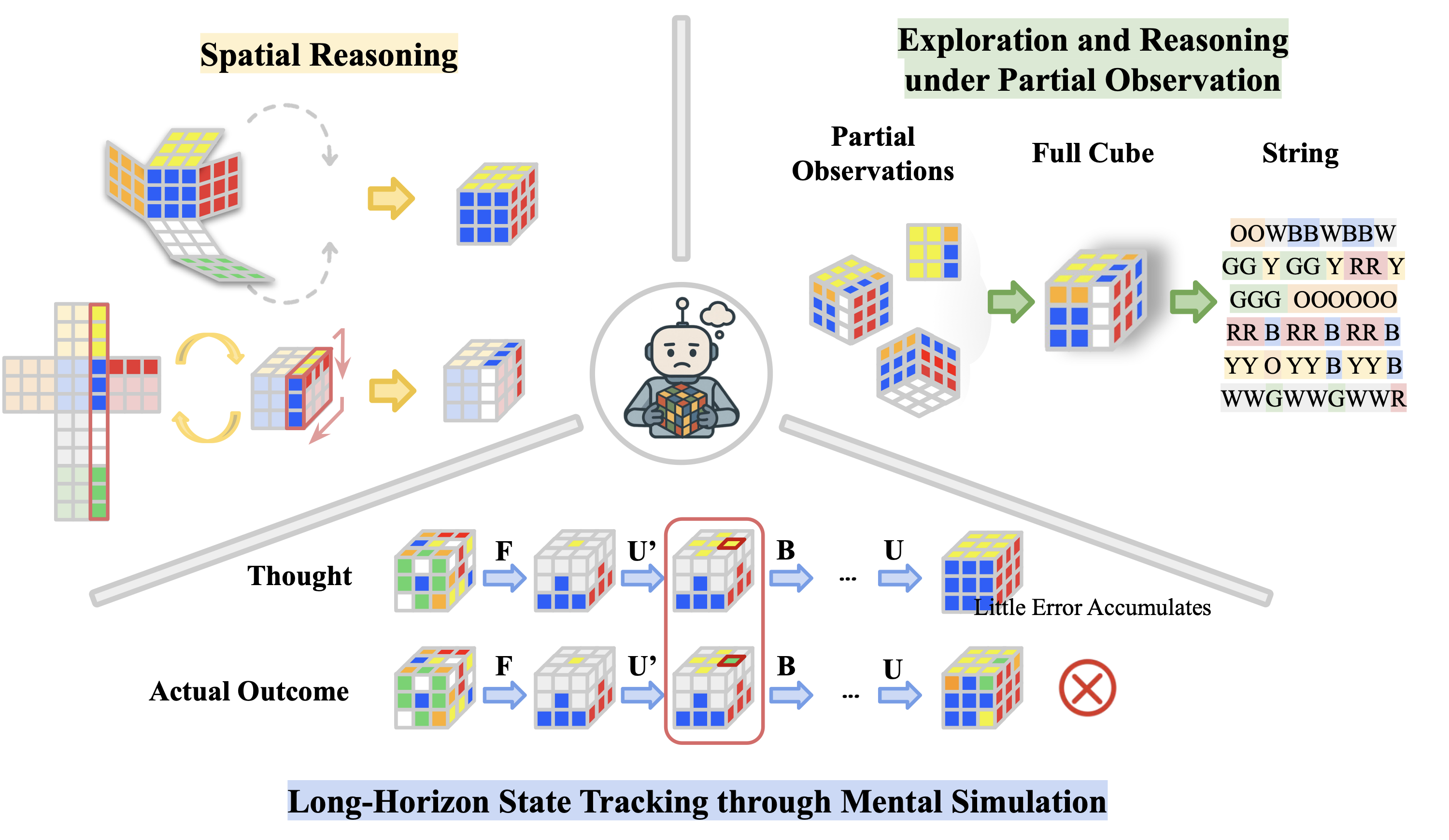
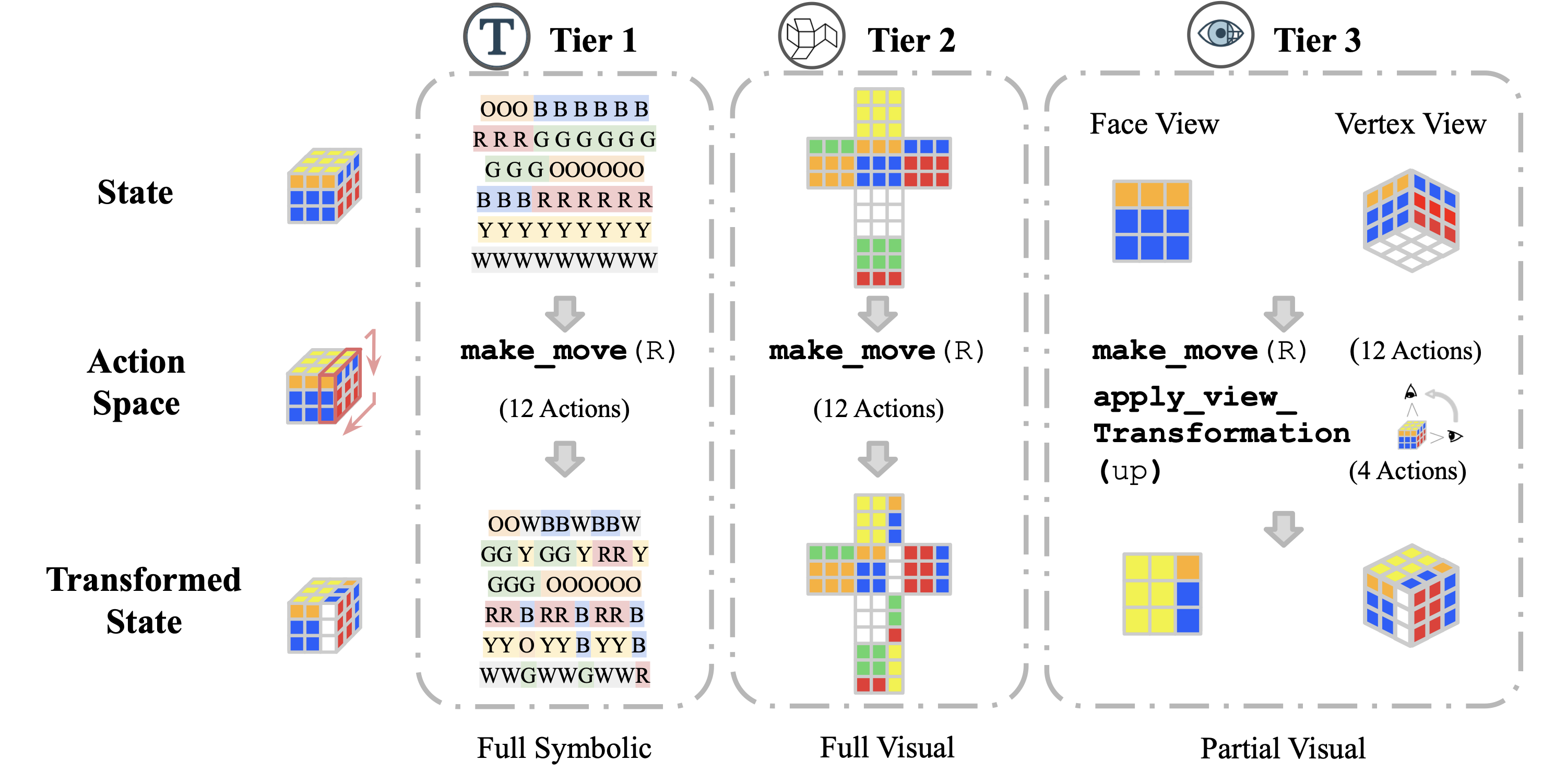
Large Language Model (LLM) agents, while proficient in the digital realm, face a significant gap in physical-world deployment due to the challenge of forming and maintaining a robust spatial mental model. We identify three core cognitive challenges hindering this transition: spatial reasoning, long-horizon state tracking via mental simulation, and active exploration under partial observation. To isolate and evaluate these faculties, we introduce CubeBench, a novel generative benchmark centered on the Rubik's Cube. CubeBench uses a three-tiered diagnostic framework that progressively assesses agent capabilities, from foundational state tracking with full symbolic information to active exploration with only partial visual data. Our experiments on leading LLMs reveal critical limitations, including a uniform 0.00% pass rate on all long-horizon tasks, exposing a fundamental failure in long-term planning. We also propose a diagnostic framework to isolate these cognitive bottlenecks by providing external solver tools. By analyzing the failure modes, we provide key insights to guide the development of more physically-grounded intelligent agents.
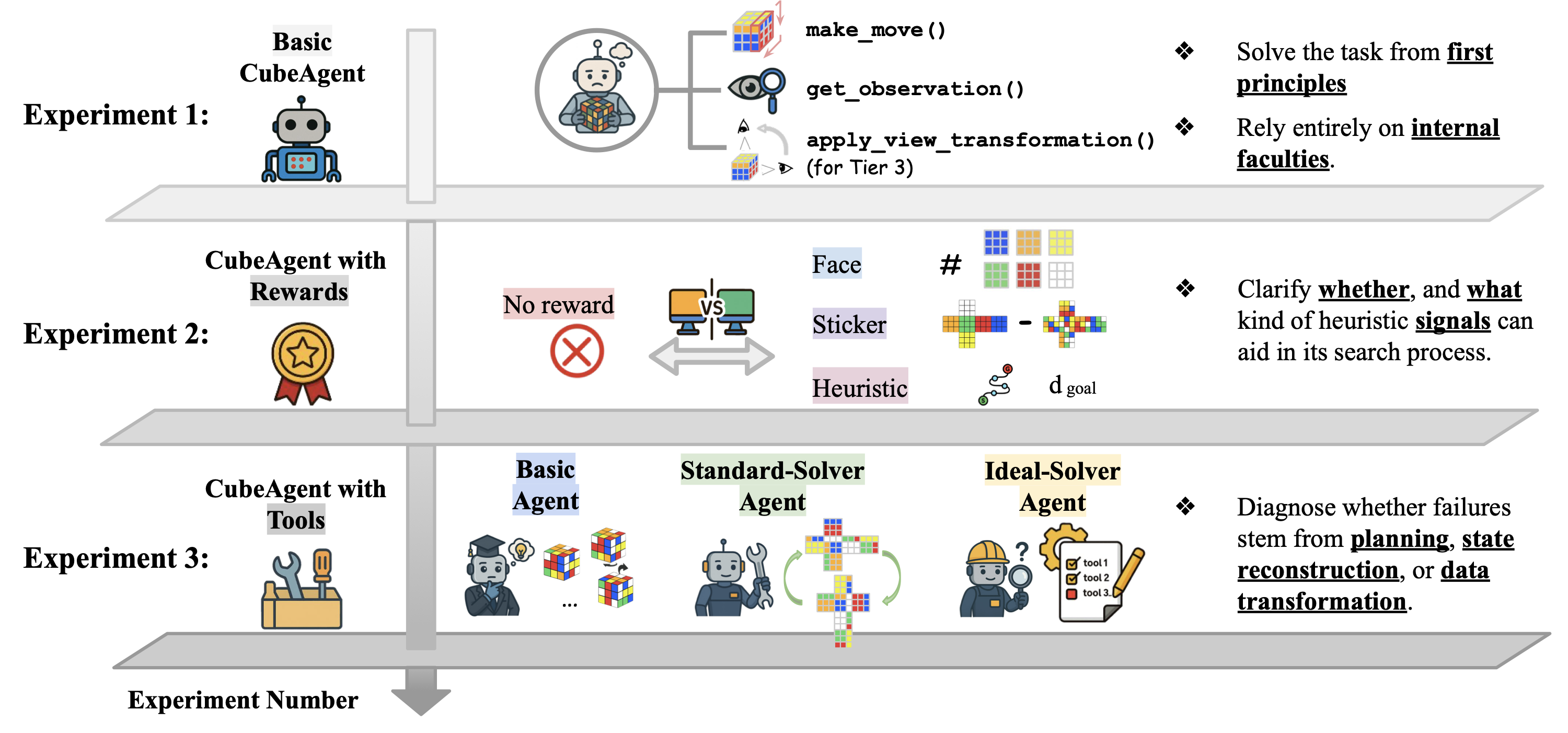
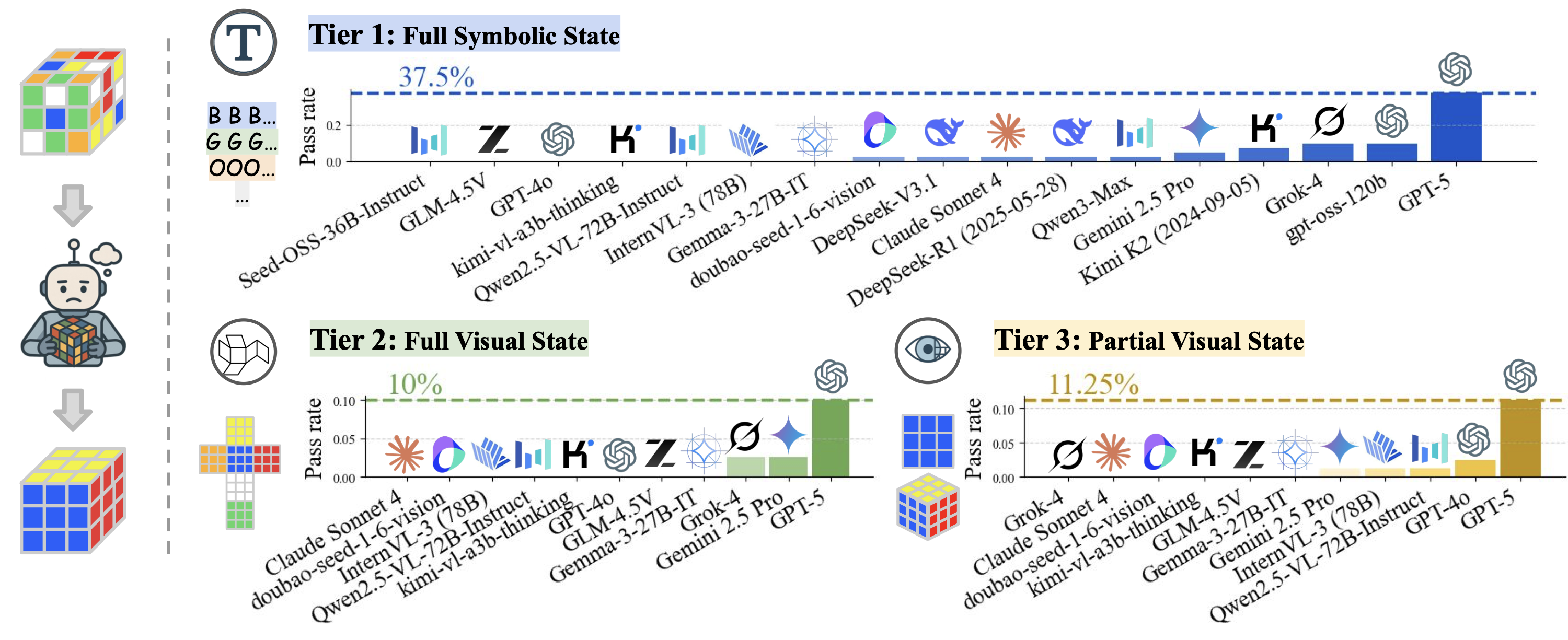
We evaluated leading LLMs across all four observation modalities on both short- and long-horizon tasks. The results reveal several critical limitations:
| Model | Full Symbolic | Full Visual | Face View | Vertex View | ||||
|---|---|---|---|---|---|---|---|---|
| S | L | S | L | S | L | S | L | |
| GPT-5 | 0.75 | 0.00 | 0.20 | 0.00 | 0.40 | 0.00 | 0.05 | 0.00 |
| MLP (Policy Gradient) | 0.75 | 0.00 | -- | -- | -- | -- | -- | -- |
| gpt-oss-120b | 0.20 | 0.00 | -- | -- | -- | -- | -- | -- |
| Grok-4 | 0.20 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Kimi K2 (2024-09-05) | 0.15 | 0.00 | -- | -- | -- | -- | -- | -- |
| Gemini 2.5 Pro | 0.10 | 0.00 | 0.05 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 |
| DeepSeek-R1 (2025-05-28) | 0.05 | 0.00 | -- | -- | -- | -- | -- | -- |
| Claude Sonnet 4 | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Qwen3-Max | 0.05 | 0.00 | -- | -- | -- | -- | -- | -- |
| DeepSeek-V3.1 | 0.05 | 0.00 | -- | -- | -- | -- | -- | -- |
| doubao-seed-1-6-vision | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| InternVL-3 (78B) | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 |
| Qwen2.5-VL-72B-Instruct | 0.00 | 0.00 | 0.00 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 |
| kimi-vl-a3b-thinking | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| GPT-4o | 0.00 | 0.00 | 0.00 | 0.00 | 0.10 | 0.00 | 0.00 | 0.00 |
| GLM-4.5V | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Gemma-3-27B-IT | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Seed-OSS-36B-Instruct | 0.00 | 0.00 | -- | -- | -- | -- | -- | -- |
Pink = Proprietary models
Blue = Open-source models
Purple = Traditional RL baseline
S = Short-horizon (depth 1-4), L = Long-horizon (depth 8-20). "--" = Model does not support visual inputs.
Critical Finding: All models show 0.00 pass rate on all long-horizon tasks.
We tested whether dense reward signals (face, sticker, and heuristic) can guide agent search:
| Model | Reward Type | Full Symbolic | Full Visual | Face View | Vertex View |
|---|---|---|---|---|---|
| GPT-5 | no reward | 0.75 | 0.20 | 0.40 | 0.05 |
| face | 0.85 | 0.55 | 0.50 | 0.40 | |
| sticker | 0.65 | 0.55 | 0.55 | 0.50 | |
| heuristic | 0.50 | 0.45 | 0.65 | 0.30 | |
| Gemini 2.5 Pro | no reward | 0.10 | 0.05 | 0.05 | 0.00 |
| face | 0.00 | 0.00 | 0.00 | 0.00 | |
| sticker | 0.10 | 0.00 | 0.05 | 0.00 | |
| heuristic | 0.05 | 0.00 | 0.10 | 0.00 | |
| Claude Sonnet 4 | no reward | 0.05 | 0.00 | 0.00 | 0.00 |
| face | 0.10 | 0.10 | 0.05 | 0.00 | |
| sticker | 0.25 | 0.15 | 0.00 | 0.05 | |
| heuristic | 0.20 | 0.05 | 0.05 | 0.10 |
Note: All long-horizon tasks remain at 0.00 pass rate regardless of reward type.
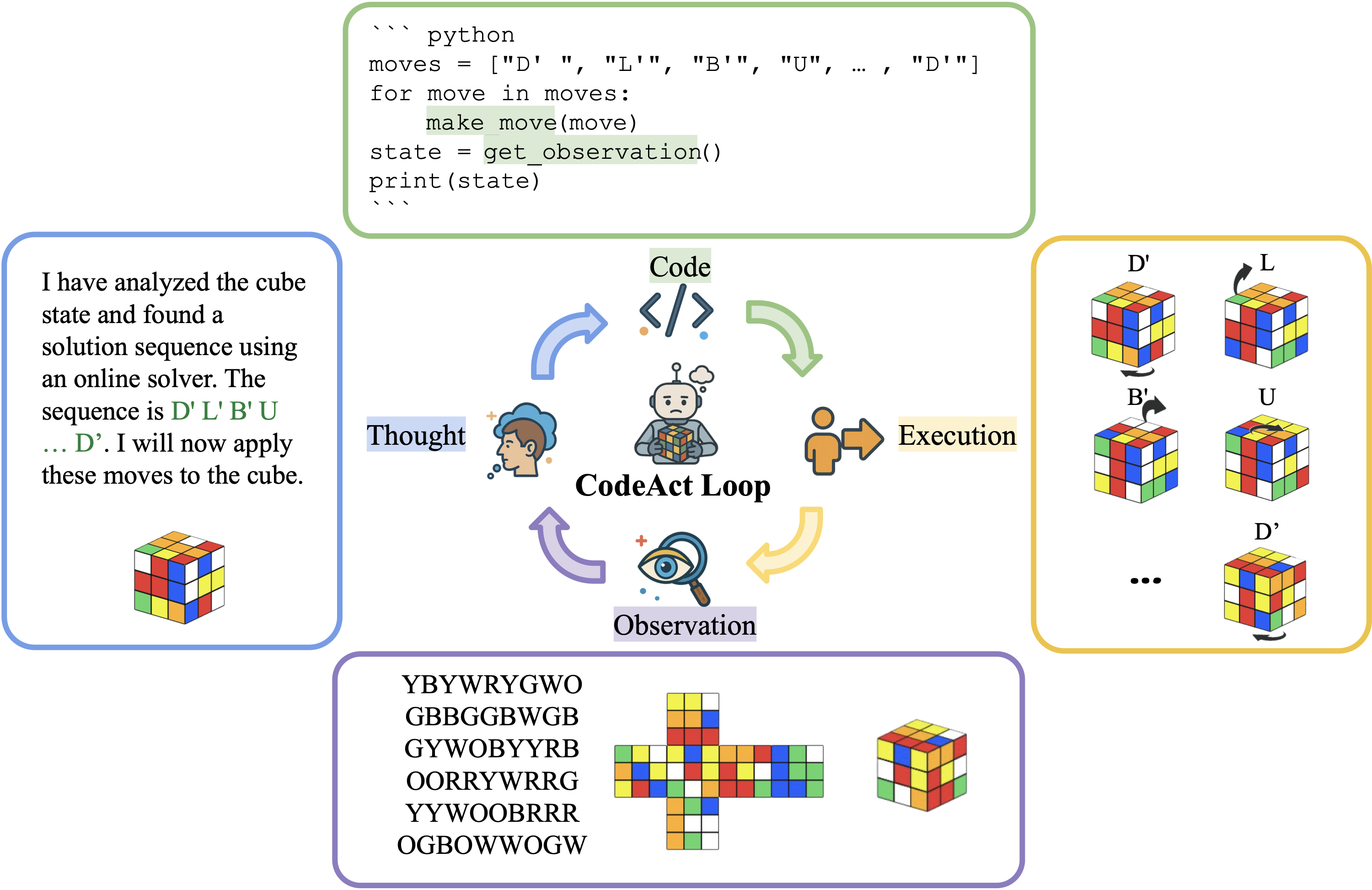
By equipping agents with optimal solvers, we isolated specific cognitive bottlenecks:
| Model | Agent Type | Full Symbolic | Full Visual | Face View | Vertex View | ||||
|---|---|---|---|---|---|---|---|---|---|
| S | L | S | L | S | L | S | L | ||
| GPT-5 | Basic | 0.75 | 0.00 | 0.20 | 0.00 | 0.40 | 0.00 | 0.05 | 0.00 |
| Standard-Solver | 0.95 | 0.95 | 0.65 | 0.70 | 1.00 | 0.95 | 0.00 | 0.00 | |
| Ideal-Solver | 1.00 | 1.00 | 0.95 | 0.80 | 0.85 | 1.00 | 0.00 | 0.00 | |
| Gemini 2.5 Pro | Basic | 0.10 | 0.00 | 0.05 | 0.00 | 0.05 | 0.00 | 0.00 | 0.00 |
| Standard-Solver | 0.70 | 0.65 | 0.25 | 0.00 | 0.20 | 0.00 | 0.00 | 0.00 | |
| Ideal-Solver | 1.00 | 1.00 | 0.25 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Claude Sonnet 4 | Basic | 0.05 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| Standard-Solver | 0.35 | 0.85 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Ideal-Solver | 1.00 | 1.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
S = Short-horizon tasks (depth 1-4), L = Long-horizon tasks (depth 8-20). Light Blue = Standard-Solver, Darker Blue = Ideal-Solver. Note the universal failure on Vertex View even with Ideal-Solver.
@article{gao2025cubebench,
title={CubeBench: Diagnosing Interactive, Long-Horizon Spatial Reasoning under Partial Observations},
author={Gao, Huan-ang and Zhang, Zikang and Luo, Tianwei and Yang, Kaisen and Juan, Xinzhe and Qiu, Jiahao and Chen, Tianxing and He, Bingxiang and Zhao, Hao and Zhou, Hao and Liu, Shilong and Wang, Mengdi},
journal={arXiv preprint arXiv:2512.23328},
year={2025}
}